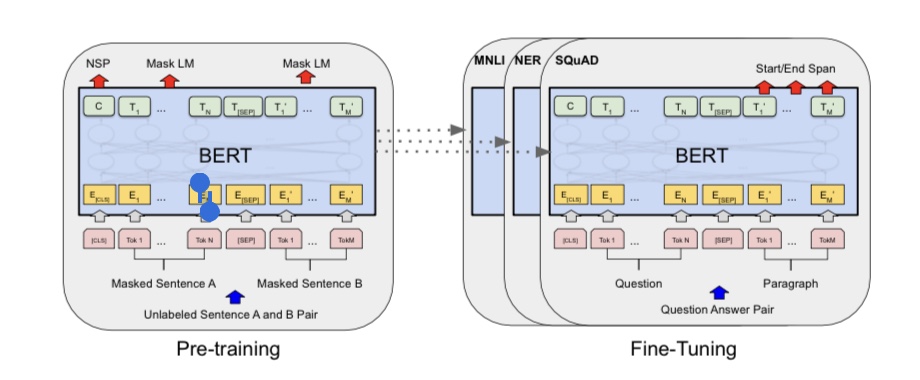
BERT (Bidirectional Encoder Representations from Transformers)는 Transformer 아키텍처를 기반으로 한 양방향 언어 모델이다. 이 모델은 대규모의 텍스트 데이터로 사전 학습(pre-training)된 후, 다양한 자연어 처리 작업에서 미세 조정(fine-tuning)을 통해 사용된다.
BERT 모델의 구조
BERT 모델은 Transformer의 인코더(Encoder)를 여러 개 쌓아 올린 구조로, 각 인코더는 다음과 같은 두 개의 서브 레이어(sub-layer)로 이루어져 있다.
Self-Attention Layer
Feed-Forward Layer
Self-Attention Layer는 입력 문장의 각 단어에 대해 문맥을 파악하고, 문장 내에서 다른 단어와의 상호작용을 고려하여 단어의 임베딩을 계산한다. 이렇게 계산된 단어 임베딩은 Feed-Forward Layer로 전달되어 출력으로 변환된다.
Feed-Forward Layer는 Self-Attention Layer에서 계산된 임베딩을 입력으로 받아, 다층 퍼셉트론(multi-layer perceptron)을 통해 출력으로 변환한다.
BERT 모델은 이러한 인코더를 여러 층으로 쌓아 올린 구조로 이루어져 있으며 이때, 각 층의 입력으로는 이전 층의 출력이 사용된다. 마지막 층의 출력은 다양한 자연어 처리 작업에서 사용될 수 있는 문장 임베딩으로 사용된다.
BERT 모델의 학습 원리
BERT 모델은 대규모의 텍스트 데이터를 사용하여 사전 학습되며 이때, 모델은 다음 두 가지 태스크를 수행하며 학습한다.
Masked Language Modeling (MLM)
Next Sentence Prediction (NSP)
Masked Language Modeling은 입력 문장에서 무작위로 일부 단어를 마스킹한 후, 마스킹된 단어를 예측하는 태스크이다. 이를 통해 모델은 문맥을 파악하고, 문장 내에서 다른 단어와의 상호작용을 고려하여 단어의 임베딩을 계산할 수 있다.
Next Sentence Prediction은 두 개의 연속된 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장의 다음 문장인지 아닌지를 예측하는 태스크이다. 이를 통해 모델은 문장 간의 관계를 학습할 수 있다.
BERT 모델은 이러한 MLM과 NSP 태스크를 동시에 학습한다. 모델은 입력 문장에서 일부 단어를 마스킹한 후, 마스킹된 단어를 예측하는데 이때 모델은 마스킹된 단어의 위치를 알 수 있지만, 해당 단어가 어떤 단어인지는 알 수 없다. 따라서, 모델은 문장 내에서 다른 단어들과의 상호작용을 고려하여 마스킹된 단어를 예측해야 한다.
또한, 모델은 두 개의 연속된 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장의 다음 문장인지 아닌지를 예측하며 이때 모델은 두 문장의 관계를 학습하고, 다양한 문장 간의 관계를 이해할 수 있다.
BERT 모델은 사전 학습 후, 다양한 자연어 처리 작업에 대해 미세 조정(fine-tuning) 된다. 이 과정에서 모델은 사전 학습된 가중치를 초기값으로 사용하고, 추가적인 데이터를 사용하여 해당 작업에 최적화된 모델을 만든다. 이를 통해 BERT 모델은 다양한 자연어 처리 작업에서 높은 성능을 보이게 된다.
샘플코드
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
# BERT 모델 로드
bert_model = hub.load("https://tfhub.dev/google/bert_uncased_L-12_H-768_A-12/3")
# 입력 문장 정의
sentences = tf.constant(["Hello, how are you?", "I am doing well, thank you!"])
# 입력 문장에 대한 BERT 임베딩 계산
bert_results = bert_model(sentences)
# 임베딩 결과 출력
print("Shape of BERT embeddings:", bert_results["pooled_output"].shape)




댓글