VAE (Variational Autoencoder) 모델은 unsupervised learning에서 많이 사용되는 모델 중 하나로, 이미지나 텍스트와 같은 고차원 데이터를 저차원의 latent space로 인코딩하는 방법을 학습한다. 이 latent space는 저차원이기 때문에 원래의 데이터보다 훨씬 작은 차원으로 표현되지만, 원래의 데이터를 충분히 잘 대표할 수 있어야 한다. latent space에서는 데이터를 다루기가 더 쉬워지기 때문에, 데이터를 압축하거나 변형하는 등의 작업을 더 효율적으로 수행할 수 있다.
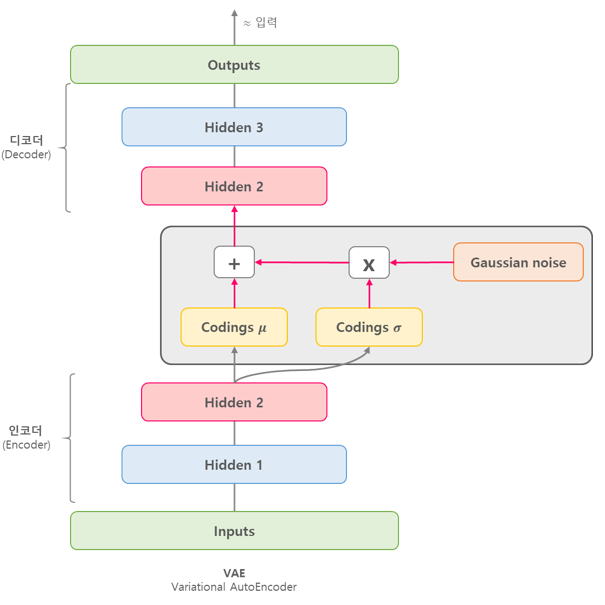
VAE 모델은 Encoder와 Decoder로 구성된다. Encoder는 입력 데이터를 latent space로 인코딩하고, Decoder는 latent space에서 원래의 입력 데이터를 재생성한다. 그리고 이 때, VAE는 인코딩된 latent space에서 임의의 샘플을 뽑아내어 이를 Decoder에 입력하여 새로운 데이터를 생성하는 것도 가능하다.
VAE 모델은 Encoder가 인코딩한 latent space가 가우시안 분포를 따른다는 가정을 한다. 이 가우시안 분포의 평균과 분산을 Encoder의 출력으로부터 추정하고, 이를 통해 latent space에서 샘플링할 수 있다. 그리고 이 샘플링 과정에서 생성된 latent vector는 Decoder를 통해 원래의 입력 데이터를 재생성하는 데 사용된다.
VAE 모델의 학습 과정은 인코딩된 latent space가 실제로 원래의 데이터를 잘 대표할 수 있도록, 원래의 입력 데이터와 재생성된 데이터의 차이를 최소화하도록 한다. 이때, VAE는 KL Divergence를 사용하여 Encoder가 출력하는 latent space의 분포와 가우시안 분포 사이의 차이를 최소화한다. 이 과정을 통해 VAE는 Encoder와 Decoder를 통해 잘 학습된 latent space를 구성하게 되며, 이를 통해 새로운 데이터 생성 및 재생성, 데이터의 변형 등 다양한 응용이 가능하다.
VAE 모델은 다양한 분야에서 사용되고 있으며, 특히 이미지나 음성, 자연어 처리 등에서 많은 성과를 내고 있다.
VAE 모델의 샘플 코드는 아래와 같다.
import tensorflow as tf
from tensorflow.keras import layers
# 데이터셋 로드 및 전처리
(x_train, _), _ = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) / 255.
# 인코더 모델 구현
latent_dim = 2
encoder_inputs = tf.keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, 3, activation="relu", strides=2, padding="same")(encoder_inputs)
x = layers.Conv2D(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Flatten()(x)
x = layers.Dense(16, activation="relu")(x)
z_mean = layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = layers.Dense(latent_dim, name="z_log_var")(x)
encoder = tf.keras.Model(encoder_inputs, [z_mean, z_log_var], name="encoder")
# 디코더 모델 구현
latent_inputs = tf.keras.Input(shape=(latent_dim,))
x = layers.Dense(7 * 7 * 64, activation="relu")(latent_inputs)
x = layers.Reshape((7, 7, 64))(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Conv2DTranspose(32, 3, activation="relu", strides=2, padding="same")(x)
decoder_outputs = layers.Conv2DTranspose(1, 3, activation="sigmoid", padding="same")(x)
decoder = tf.keras.Model(latent_inputs, decoder_outputs, name="decoder")
# VAE 모델 구현
class VAE(tf.keras.Model):
def __init__(self, encoder, decoder, **kwargs):
super(VAE, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def encode(self, x):
z_mean, z_log_var = self.encoder(x)
return z_mean, z_log_var
def reparameterize(self, z_mean, z_log_var):
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.keras.backend.random_normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
def decode(self, z):
return self.decoder(z)
def call(self, x):
z_mean, z_log_var = self.encode(x)
z = self.reparameterize(z_mean, z_log_var)
reconstructed = self.decode(z)
kl_loss = -0.5 * tf.reduce_mean(
z_log_var - tf.square(z_mean) - tf.exp(z_log_var) + 1
)
self.add_loss(kl_loss)
return reconstructed
# 모델 컴파일 및 학습
vae = VAE(encoder, decoder)
vae.compile(optimizer=tf.keras.optimizers.Adam())
vae.fit(x_train, epochs=30, batch_size=128)




댓글