Zero-shot learning의 개념
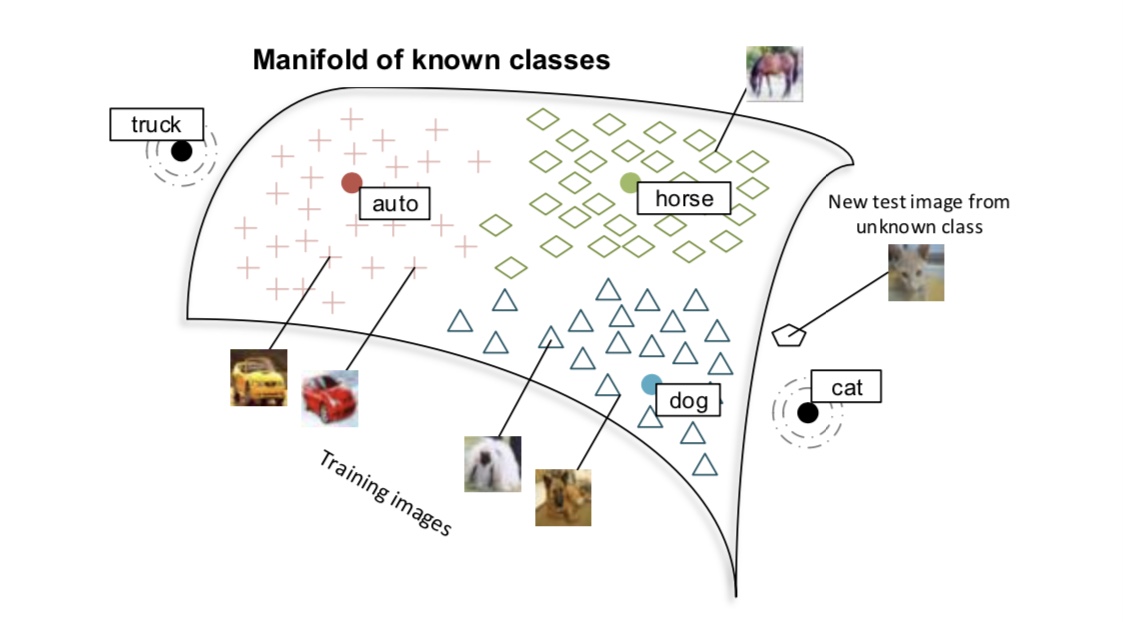
Zero-shot learning은 기존의 supervised learning과는 달리, 새로운 클래스에 대한 학습 데이터가 주어지지 않았을 때도 새로운 클래스를 인식하고 분류하는 능력을 가진 기계 학습 방식이다.
이를 통해 모델이 기존에 학습하지 않은 새로운 클래스에 대해 예측하는 능력을 가지게 된다.
Zero-shot learning은 특히, 새로운 클래스가 계속해서 추가되는 동적인 환경에서 유용하게 사용될 수 있으며 이를 통해 새로운 데이터셋에 대한 학습을 반복할 필요 없이, 새로운 클래스를 인식하고 분류할 수 있다.
Zero-shot learning의 구조
Zero-shot learning의 구조는 대부분의 기계 학습 모델과 유사하지만, Zero-shot learning에서는 추가적인 데이터셋이나 정보를 사용하여 모델이 새로운 클래스를 학습할 수 있도록 한다.
이를 위해, 다양한 문제에 대해 다양한 정보를 이용하여 학습된 사전 모델이 사용될 수 있다.
예를 들어, 자연어 처리 분야에서 Zero-shot learning을 수행하는 경우, 사전 모델로 미리 학습된 언어 모델을 사용할 수 있다. 이를 통해, 새로운 클래스에 대한 설명이나 키워드를 입력하여 해당 클래스를 분류할 수 있다.
Zero-shot learning의 샘플코드
Zero-shot learning의 샘플코드는 다양한 분야에서 활용될 수 있는데 아래는 자연어 처리 분야에서의 Zero-shot learning 예제 코드이다.
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("bert-base-uncased")
model = transformers.AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
# 클래스 레이블 정의
class_labels = ["positive", "negative", "neutral"]
# Zero-shot learning 예측
def zero_shot_classification(text, class_labels):
# 입력 텍스트 토큰화
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
# 클래스 레이블 토큰화
labels = [tokenizer(label, padding=True, truncation=True, return_tensors="pt")["input_ids"] for label in class_labels]
labels = torch.stack(labels)
# 모델 예측
outputs = model(**inputs, labels=labels)
logits = outputs.logits
# 클래스 레이블 예측
_, indices = torch.sort(logits, descending=True)
predicted_class = class_labels[indices[0][0]]
return predicted_class
위 코드에서는 Hugging Face의 Transformers 라이브러리를 사용하여 Zero-shot learning 분류 모델을 구현하고 있다.
모델로는 BERT를 사용하며, 입력 텍스트와 클래스 레이블을 토큰화하여 모델 입력으로 사용한다. 이를 통해, 모델은 입력 텍스트와 클래스 레이블 간의 관계를 학습하고, 새로운 클래스에 대해 예측을 수행한다.
예측을 위해, 모델 출력값의 최대값을 가지는 클래스 레이블을 예측 결과로 반환하며 이 결과로 모델이 새로운 클래스에 대해 예측하는 능력을 확인할 수 있다.




댓글