RoBERTa는 Facebook AI Research(Facebook AI)에서 개발한 언어 모델로 Transformer 아키텍처에 기반하며, BERT 모델의 성능을 대폭 향상시켰다. RoBERTa 모델의 구조는 BERT 모델과 매우 유사하지만, RoBERTa는 BERT에서 사용된 pre-training 데이터셋에 대한 전처리를 다시 수행하여 모델 학습에 사용한다.
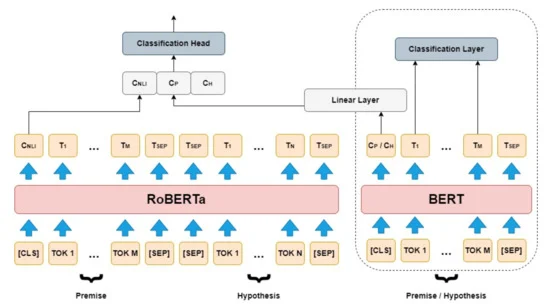
예를 들어, RoBERTa는 문장을 뒤섞는 방식 대신 문장을 연속적으로 나열하는 방식을 사용한다.
이를테면, "I like to eat apples"와 "Apples are my favorite fruit"라는 두 문장이 있을 경우, BERT는 "I like to eat apples" 다음에 "Apples are my favorite fruit"이라는 문장이 나오는 것을 예측하는 방식으로 학습된다.
하지만 RoBERTa는 두 문장을 연속적으로 합쳐서 "I like to eat apples Apples are my favorite fruit" 라는 문장으로 만든 다음 이 문장을 뒤섞는 것이 아니라, 그대로 입력으로 사용한다.
아래는 RoBERTa 모델을 개념적으로 구현한 샘플 코드이다.
import torch
import torch.nn as nn
class RoBERTa(nn.Module):
def __init__(self, vocab_size, embedding_size, num_heads, num_layers):
super(RoBERTa, self).__init__()
self.token_embedding = nn.Embedding(vocab_size, embedding_size)
self.position_embedding = nn.Embedding(512, embedding_size)
self.dropout = nn.Dropout(0.1)
self.layers = nn.ModuleList()
for i in range(num_layers):
layer = nn.TransformerEncoderLayer(embedding_size, num_heads, dim_feedforward=4*embedding_size)
self.layers.append(layer)
self.layernorm = nn.LayerNorm(embedding_size)
def forward(self, x):
positions = torch.arange(x.size(1), device=x.device).expand(x.size(0), x.size(1)).contiguous() + 1
tokens_embed = self.token_embedding(x)
positions_embed = self.position_embedding(positions)
x = self.dropout(tokens_embed + positions_embed)
for layer in self.layers:
x = layer(x)
x = self.layernorm(x)
return x
RoBERTa 모델은 pre-training 데이터셋을 사용하여 먼저 언어 모델을 학습한 다음, fine-tuning을 통해 다양한 태스크에 적용될 수 있도록 조정된다. Pre-training 단계에서 RoBERTa는 MLM(Masked Language Modeling) 및 NSP(Next Sentence Prediction) 태스크를 수행하며, 이를 통해 문장 내의 단어 간 관계와 문장 간의 관계를 이해하게 된다.
아래는 Hugging Face Transformer 라이브러리를 사용하여 RoBERTa 모델을 구현하는 샘플 코드이다.
import torch
from transformers import RobertaTokenizer, RobertaModel
# RoBERTa 토크나이저 로드
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
# RoBERTa 모델 로드
model = RobertaModel.from_pretrained('roberta-base')
# 입력 문장
input_sentence = "I love to use RoBERTa!"
# 입력 문장 토큰화
input_ids = torch.tensor([tokenizer.encode(input_sentence, add_special_tokens=True)])
# RoBERTa 모델에 입력 문장 적용
output = model(input_ids)
# 출력 확인
print(output)위 코드에서는 RoBERTaTokenizer와 RobertaModel을 사용하여 RoBERTa 모델을 로드하고, 입력 문장을 토큰화한 다음 RoBERTa 모델에 입력하여 출력을 확인한다. 이 코드를 실행하면, 입력 문장의 임베딩이 출력되며, 출력은 (batch_size, sequence_length, hidden_size)의 형태로 나타나게 된다.
'Dev' 카테고리의 다른 글
| ALBERT (0) | 2023.03.19 |
|---|---|
| XLM (0) | 2023.03.17 |
| DistilBERT (0) | 2023.03.12 |
| Zero-shot learning (0) | 2023.03.11 |
| GPT-3 (0) | 2023.03.10 |




댓글