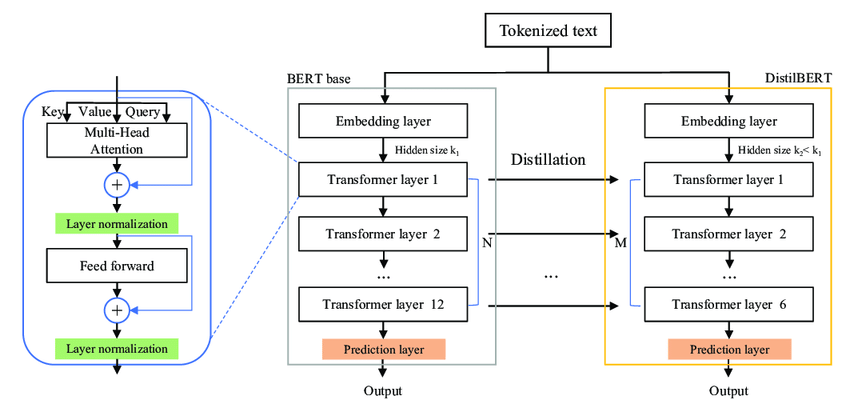
DistilBERT는 Hugging Face에서 개발한 경량화된 버전의 BERT(Bidirectional Encoder Representations from Transformers) 모델이다. BERT는 대규모 모델이기 때문에, 작은 디바이스나 컴퓨팅 자원이 한정된 환경에서는 사용하기 어려워 Hugging Face에서는 BERT 모델의 크기를 대폭 축소한 DistilBERT 모델을 개발하였다.
DistilBERT의 개념
DistilBERT는 BERT 모델의 아키텍처를 유지하되, 불필요한 파라미터를 제거하고, 파라미터를 공유하여 모델 크기를 대폭 축소하였다. 이를 통해, BERT 모델의 성능을 대폭 저하시키지 않으면서도, 작은 디바이스에서도 사용할 수 있는 모델을 제공한다.
DistilBERT의 구조
DistilBERT는 다음과 같은 특징을 가지고 있다.
1. 레이어 수 줄이기
BERT 모델에서는 12개의 Transformer 레이어를 사용하지만 DistilBERT에서는 6개의 Transformer 레이어를 사용하여 모델 크기를 줄였다. 이를 통해, 모델의 크기와 계산 비용을 대폭 줄일 수 있다.
2. 파라미터 공유
DistilBERT에서는 각 Transformer 레이어의 파라미터를 공유하여 모델 크기를 더욱 줄일 수 있다.
3. 토크나이저 크기 줄이기
DistilBERT에서는 BERT 모델의 토크나이저보다 작은 크기의 토크나이저를 사용한다. 이를 통해, 모델 크기를 더욱 축소할 수 있으며, 입력 데이터를 더욱 효율적으로 처리할 수 있다.
4. 임베딩 차원 줄이기
DistilBERT에서는 BERT 모델과 달리, 임베딩 차원을 768에서 512로 줄여서 모델 크기를 더욱 축소할 수 있다.
아래는 DistilBERT 의 구조를 간략하게 구현한 샘플코드이다.
class DistilBertModel(nn.Module):
def __init__(self):
super(DistilBertModel, self).__init__()
self.embeddings = nn.Embedding(30522, 512)
self.transformer = nn.Sequential(
TransformerLayer(512, 2048, 6),
TransformerLayer(512, 2048, 6),
TransformerLayer(512, 2048, 6),
TransformerLayer(512, 2048, 6),
TransformerLayer(512, 2048, 6),
TransformerLayer(512, 2048, 6)
)
def forward(self, input_ids):
embeddings = self.embeddings(input_ids)
attention_mask = input_ids.ne(0).float()
hidden_states = embeddings
for layer in self.transformer:
hidden_states = layer(hidden_states, attention_mask)
return hidden_states
class TransformerLayer(nn.Module):
def __init__(self, hidden_size, intermediate_size, num_attention_heads):
super(TransformerLayer, self).__init__()
self.attention = nn.MultiheadAttention(hidden_size, num_attention_heads)
self.intermediate = nn.Sequential(
nn.Linear(hidden_size, intermediate_size),
nn.ReLU(inplace=True),
nn.Linear(intermediate_size, hidden_size),
)
self.layer_norm1 = nn.LayerNorm(hidden_size, eps=1e-12)
self.layer_norm2 = nn.LayerNorm(hidden_size, eps=1e-12)
def forward(self, hidden_states, attention_mask):
attention_output, _ = self.attention(hidden_states, hidden_states, hidden_states, key_padding_mask=(attention_mask == 0))
attention_output = self.layer_norm1(attention_output + hidden_states)
intermediate_output = self.intermediate(attention_output)
layer_output = self.layer_norm2(intermediate_output + attention_output)
return layer_output
DistilBERT의 활용
DistilBERT 모델은 Hugging Face Transformers 라이브러리를 통해 쉽게 구현할 수 있다.
아래는 DistilBERT 모델을 사용하여 문장 분류를 수행하는 샘플 코드이다.
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
# 모델 및 토크나이저 로드
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')
# 입력 문장 토큰화 및 모델 입력 형식으로 변환
text = "This is an example sentence to classify."
tokens = tokenizer.encode_plus(text, padding='max_length', truncation=True, return_tensors='pt')
input_ids = tokens['input_ids']
attention_mask = tokens['attention_mask']
# 문장 분류 수행
outputs = model(input_ids, attention_mask)
logits = outputs.logits
predicted_class_idx = torch.argmax(logits, dim=-1).item()
# 예측된 클래스 출력
class_names = ['Class 1', 'Class 2', 'Class 3']
predicted_class_name = class_names[predicted_class_idx]
print("Predicted class:", predicted_class_name)
위 코드에서는 DistilBERT 모델과 토크나이저를 로드하고, 입력 문장을 토큰화하여 모델 입력 형식으로 변환한다. 그리고, 모델을 사용하여 입력 문장의 클래스를 분류하고, 예측된 클래스를 출력한다.




댓글