논문 출처 : Y Dokuz, Z Tufekci - Applied Acoustics, 2021 - Elsevier
1. 요약
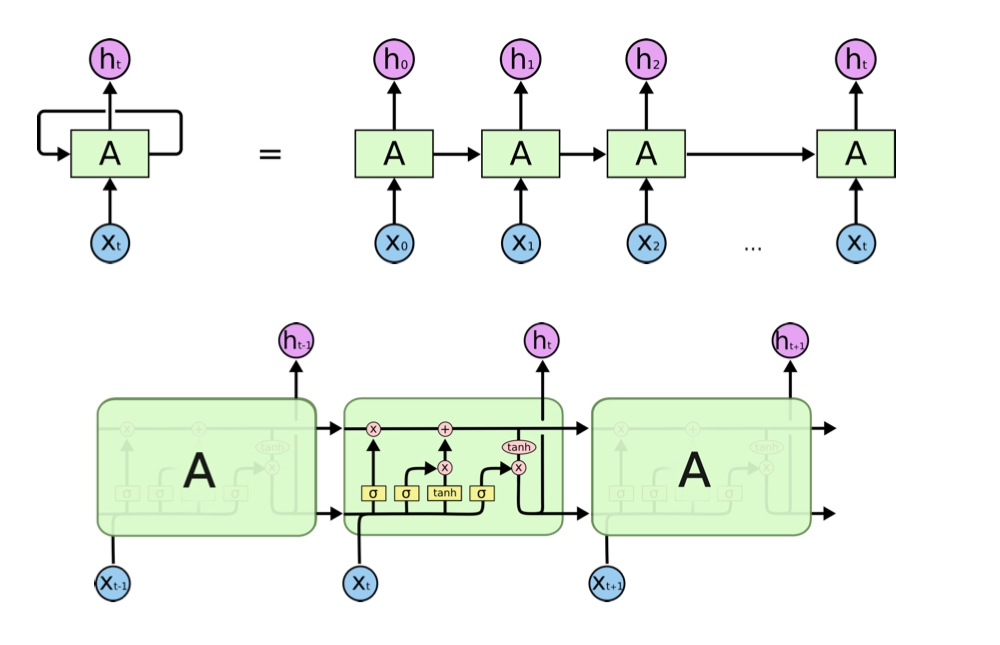
RNN 은 순환 신경망이라고 부르며, 자연어 처리나 음성 인식처럼 순서가 있는 데이터를 처리하는데 강점이 있는 신경망이다.
앞 단계에 입력된 값에 대해 처리한 결과를 다음 단계에서 참조해 나가는 형태로 처리하며 이를 통해 입력된 순서에 따라 단계별로 출력을 발생시킨다.
그러나 이 단계가 길어지는 경우 맨 앞의 정보에 대해 맨 뒤에서 기억하지 못하는 한계가 발생하게 되는데 이러한 한계를 보완한 것이 LSTM 이다. 또한 음성 데이터를 입력 받았을 때 어디서부터 어디까지가 하나의 음소인지 각각 라벨링 처리를 진행해주지 않으면 인식률이 떨어지게 되기 때문에 라벨링을 진행해 줘야 하나 MFCC 와 같은 잘개 쪼개진 데이터의 경우 임의로 라벨링을 하기가 어렵다.
이럴 때 CTC 알고리즘을 사용하게 되면, 임의로 분할된 각 영역마다 해당되는 특징에 대해 확률적으로 예측하여 결과값을 얻게 된다.
이 논문에서는 추출된 MFCC 데이터를 LSTM 과 CTC 를 통해 처리하여 음성인식을 진행하는 과정에서
앞 단계에 미니 배치 샘플 선택 부분을 도입하여 더 정확한 결과물을 얻고자 하는 연구이다.
2. 결론
실험 결과 성별의 경우 동일한 성별로 사전 처리를 진행한 데이터에 대해서 예측률이 높게 나타났으며, 엑센트의 경우 서로 다른 엑센트로 구분하여 사전 처리를 진행하였을 때 예측률이 높게 나왔다.
결국 동일한 성별을 하나의 미니 배치 샘플로 선택하는 것이 출력 텍스트로 음성 입력을 더 잘 모델링하게 되고
또한 다양한 액센트가 존재할 때 딥러닝 시스템은 가능한 모든 액센트를 학습할 수 있기 때문에 더욱 예측률이 높게 나타나게 된다.
이러한 모든 결과를 평가할 때, 성별과 엑센트 메타정보가 미니 배치 샘플 선택에 사용될 때, 딥러닝 모델이 더 나은 성능을
달성할 수 있다는 결론을 내릴 수 있다.
3. 느낀점
음성인식에 사용되는 딥러닝 알고리즘 중 RNN, LSTM 에 대해 깊이 있게 공부할 수 있었으며,
입력에 사용하는 데이터의 퀄리티에 따라 성능이 달라지기 때문에 초기 입력값을 어떤 식으로 전처리 하여 반영하는지에 대해서
많이 고민해봐야 한다는 것을 느낄 수 있었다.
또한 이 연구에서는 억양과 성별에 따른 분류만 진행하여 데이터를 입력하였으나 만약 다양한 언어의 모델이 반영된 알고리즘을 통해
데이터 전처리를 진행하게 된다면 해당 언어의 화자에 대한 음성인식률이 더 올라가지 않을까 라는 생각이 들었다.
'Dev' 카테고리의 다른 글
| [React Native] Invariant Violation: "main" has not been registered. (0) | 2025.01.28 |
|---|---|
| Deep residual learning for image recognition (0) | 2023.05.03 |
| 딥러닝 기반 음성인식 (0) | 2023.05.01 |
| DenseNet (0) | 2023.04.30 |
| [maven] This build requires at least…, update your JVM, and run the build again (0) | 2023.04.24 |



댓글