논문 출처 : K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, Proceedings of the IEEE conference on computer vision and pattern recognition (2016), pp. 770-778
딥러닝의 성능을 좌우하는 요소는 여러가지가 있다.
특히 통제 가능한 변수들을 하이퍼파라미터라고 하는데, 하이퍼파라미터의 최적값을 찾아가는 것이 딥러닝의 본질이기도 하다.
그러나 이러한 하이퍼파라미터를 조정하는 것 외에도, 신경망의 깊이 또한 딥러닝의 성능과 연관이 있다.
다만 한 가지 중요한 지점은 단순히 신경망의 깊이가 깊어진다고 해서 성능이 개선되지는 않는다는 것이다.
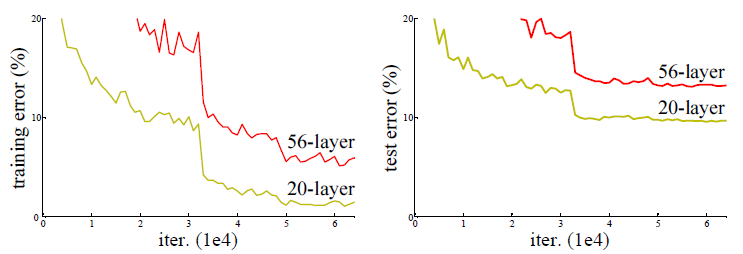
출처 : K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, Proceedings of the IEEE conference on computer vision and pattern recognition (2016), pp. 770-778
위와 같이 더 깊은 구조를 갖는 56층의 네트워크가 20층의 네트워크보다 더 나쁜 성능을 보이고 있다.
이 점에 착안하여 깊은 구조에서 성능 향상을 이끌어내기 위한 방안이 제시되었는데, 이것이 ResNet 이다.

출처 : K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, Proceedings of the IEEE conference on computer vision and pattern recognition (2016), pp. 770-778
ResNet 의 핵심 개념은 바로 위와 같은 Residual Block 을 활용하는 것이다.
기존의 인공신경망이 입력값 x를 타겟값 y와 가장 근사하게 만드는 함수 H(x) 를 얻는 것이 목적이었다면, ResNet은 F(x) + x 가 최소화 되는 것을 목적으로 한다.
이때 입력값 x 는 변하지 않는 값이기 때문에 결국 F(x)가 0에 가깝게 만드는 것이며, 이것은 출력과 입력이 모두 x로 같아지게 만든다는 의미가 된다.
F(x) = H(x) - x 이므로, 결국 F(x)를 최소로 한다는 이야기는 H(x) - x 를 최소화 한다는 의미이며, H(x) - x 는 바로 잔차(Residual)이다.
즉, ResNet 은 결국 잔차를 최소화 하는 프로세스인 것이다.

출처 : K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, Proceedings of the IEEE conference on computer vision and pattern recognition (2016), pp. 770-778
ResNet 의 계층은 위와 같이 다양하게 구성이 가능하며, 물론 152 layer의 ResNet이 가장 성능이 뛰어나다.

출처 : K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, Proceedings of the IEEE conference on computer vision and pattern recognition (2016), pp. 770-778
plain 형태의 딥러닝 모델과 달리 ResNet 모델에서는 층이 깊어질수록 오류율이 낮아지는 것을 볼 수 있다.
'Dev' 카테고리의 다른 글
| LibriSpeech 기반 ResNet, DenseNet, 그리고 앙상블 모델 개발기 (0) | 2025.01.30 |
|---|---|
| [React Native] Invariant Violation: "main" has not been registered. (0) | 2025.01.28 |
| Mini-batch sample selection strategies for deep learning based speech recognitio (0) | 2023.05.02 |
| 딥러닝 기반 음성인식 (0) | 2023.05.01 |
| DenseNet (0) | 2023.04.30 |


댓글